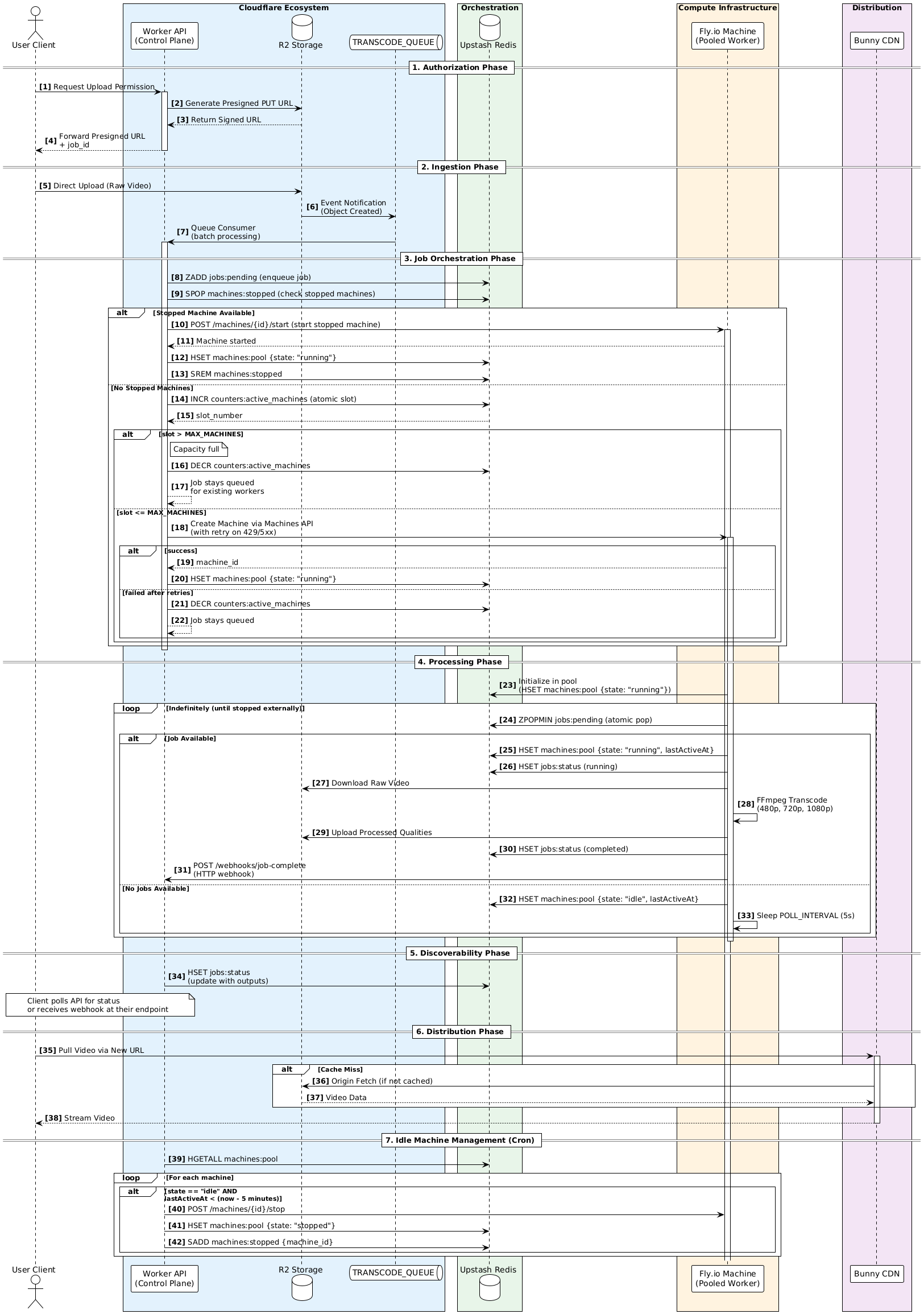
TCoder is an event-driven transcoding pipeline. The client uploads to R2 with a presigned URL, R2 fires a Queue event into a Cloudflare Worker control plane, the Worker hands the job to a Fly.io machine running FFmpeg, with Redis as the orchestration layer. Machines spin up when needed and shut themselves down when the job’s done. No central queue, no 24/7 backend. Code at v0id-user/tcoder.
I’ve always been curious about how companies like YouTube move a video from the “uploaded” stage to “ready to watch in multiple qualities.”
Instead of spending hours reading theoretical articles, I decided to build a real system that performs the entire process from start to finish.
That’s how TCoder was born: an event-driven, serverless video transcoding system designed to mimic large-scale media pipelines, but on a smaller and more approachable scale.
The Idea in Simple Terms
The flow works like this:
The client uploads a video directly to Object Storage using a presigned URL.
Once the upload finishes, the storage layer emits an event. The Control Plane receives that event, checks the system’s current capacity, and assigns the job to a worker.
These workers are temporary machines that run FFmpeg, upload the resulting outputs, and then shut themselves down once the job is done.
All coordination happens through Redis.
There’s no central job queue and no backend running 24/7.
Technologies Used
- Cloudflare Workers Acts as the Control Plane (the orchestrating brain of the system).
- Cloudflare R2 & Queues Handle uploads and deliver the events that trigger processing.
- Upstash Redis Stores system state and coordinates orchestration.
- Fly.io Machines Used to run flexible FFmpeg workers.
- Bun + TypeScript Used everywhere to keep the stack consistent.
- Bunny CDN Distributes the final content to the edge with control available through a Middleware layer. https://github.com/v0id-user/tcoder-middleware
What I wanted to explore wasn’t just “how to transcode a video.”
What interested me more was how the systems around that process behave.
For example:
- Controlling admission based on available machine pool capacity instead of launching a new machine for every request.
- Reusing idle machines to avoid cold starts and reduce costs.
- Using Redis as a transparent orchestration layer for tasks, leases, and machine states.
The workers are designed to run indefinitely if needed, while still allowing me to safely terminate them when necessary.
Why I Chose Cloudflare
I’ve been using Cloudflare for a long time, and one reason I like it is that it removes a lot of the friction that usually kills the developer experience.
Their DX is extremely consistent.
Workers, R2, and Queues feel like a single integrated platform, not separate services glued together with complicated IAM policies (my dislike for AWS is endless).
When you’re designing a system architecture, that consistency makes a huge difference.
Their storage event system is also straightforward.
As soon as an upload finishes in R2, an event can be pushed directly to a Queue, which is exactly what any data-processing pipeline needs.
Another major advantage is startup speed.
Workers aren’t just “acceptable” in terms of cold start performance like Lambda. They’re actually fast.
The most important thing though is that Workers force you to be stateless.
And that turned out to be a good thing.
It pushed me to design explicit state transitions in Redis, which made the system easier to understand, easier to inspect, and even easier to intentionally break while testing.
Why Fly.io?
This is where things got interesting.
I didn’t start with Fly.io. My first attempt was to build the project on AWS, but it simply didn’t work out.
In the region I’m in, just creating the account, connecting services, and configuring the initial setup took far longer than expected.
Instead of focusing on the system architecture, I found myself stuck fighting platform configuration and complexity.
For a learning project, that kind of friction is completely unacceptable.
Could I have built it using Lambda, SQS, and Step Functions?
Absolutely. It would probably have been easier.
But it would also hide the mechanical details I actually wanted to learn.
Running FFmpeg on Lambda is technically possible, but it quickly becomes painful.
File size limits, execution limits, temporary storage, and timeouts all turn the project into a constant exercise in working around platform constraints instead of designing a proper system.
So I changed direction and said:
fine, I’ll do it myself.
Fly.io gave me full control over the machine lifecycle.
I can spin up a VM, run FFmpeg, watch Redis indefinitely, and shut the machine down once the job finishes.
It’s not “serverless” in the traditional sense, but it is elastic infrastructure, which is actually much closer to how large media systems operate.
The idea was to treat machines as temporary workers.
They’re not pets that require constant care, and they’re not completely disposable cattle either.
They sit somewhere in between.
They exist when needed, stop when work is finished, and can be reused aggressively to avoid cold start delays.
Redis became the orchestration layer not because it’s necessarily better than managed queues, but because it keeps the system visible.
Everything is transparent:
- the task queue
- machine leases
- worker pool state
You can see everything directly and fix it if something breaks.
Tradeoffs
I know the system is more complex than simply using a managed service.
I know Redis is doing work that a managed queue could handle.
And I had to design my own admission control and cleanup processes.
But honestly?
It was a lot of fun.
This project exists primarily as a learning experiment to understand how media systems behave under pressure, during failures, and while scaling.
All architectural decisions, state models, and tradeoffs are documented in the repository’s README.
Full Architecture
Project repository: https://github.com/v0id-user/tcoder
This English version of the article was translated with the help of AI. Because the original post was written in Arabic, some nuances or details may not have transferred perfectly in the translation. For the most accurate version, you may prefer reading the original Arabic article.